

빅데이터·인공지능(AI) 분석 과정에서 주어진 데이터셋의 정보를 파악하기 위한 작업을 'EDA'라는 '탐색적 데이터 분석' 작업을 거쳐야 합니다. 이 과정에서 파악한 정보를 통해 어떤 전처리, 모델링 등 시행해야할지 판단되기 때문에 데이터 분석에 있어서 매우 중요한 단계입니다.
오늘은 EDA를 위해 매우 간단하면서 자주 활용되는 주요 pandas 함수를 기록할 것입니다. (제 remind를 위한 글...)
1. 기초 통계 지식을 활용한 분석
import numpy as np
import pandas as pd기본적으로 활용되는 numpy와 pandas를 import

head() : 첫 5행 데이터를 보여줌
tail() : 마지막 5행 데이터를 보여줌
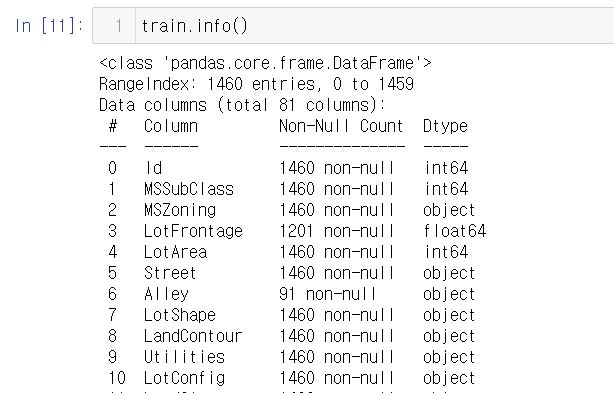

train.info() : 데이터 Column과 그 데이터 값에 대한 정보를 보여줌
train.shape : 데이터 행렬 (테이블)의 형태를 보여줌
#데이터값의 평균
train.mean()
#데이터값의 표준편차
train.std()
#null 관련
train.isnull() : 데이터 null 값들을 보여줌
train.isnull().sum() : 컬럼별로 null 값의 갯수를 보여줌
train.isnull().sum().sum() : 전체 데이터셋의 null 값의 갯수를 보여줌

train.describe() : 데이터셋의 각 통계값들을 정리해서 보여줌 (평균, 최대, 최소, 사분위값 등)

위 함수들은 DataFrame(2차원)에는 활용하지 못하고, Series(1차원)에만 넣을 수 있음
train['컬럼값'].unique() : 해당 컬럼에 나타나는 값들을 보여줌
train['컬럼값'].value_counts() : 각 값들이 몇 개씩 있는지 보여줌
train['컬럼값'].dtype : 해당 컬럼의 데이터 타입(int, float, object)을 보여줌 (참고로, object 타입만 'O'라고 뜸)
2. 시각화를 활용한 분석
import matplotlib.pyplot as plt시각화를 위한 라이브러리는 여러가지가 있지만, 간단한 주요 함수만 살펴볼 것이므로 일단은 matplotlib을 활용해봄

특정 컬럼값을 지정해서 입력해야함. 특히, plt.hist는 자주 사용됨

plt.scatter(X축, Y축) : X축(컬럼)과 Y축(컬럼) 간의 '산점도'를 찍어준다.

train.plot() : 모든 컬럼의 데이터 그래프를 그려줌 → 거의 사용하지 않음

train[ [컬럼1, 컬럼2] ].plot() : 보고 싶은 컬럼값만 그려줌. 반드시 [ ] 안에 [ ]로 다시 묶어줘야함

train['컬럼'].plot.hist() : 특정 컬럼값을 '막대 그래프'로 보여줌

train['컬럼'].plot.box() : 특정 컬럼값을 '박스플롯 그래프'로 보여줌

train['컬럼'].plot.kde() : 특정 컬럼값을 '밀도 그래프'로 보여줌
여기까지 EDA를 위한 매우 간단한 pandas와 matplotlib 함수...
특히, info(간단 정보), describe(주요 통계 수치), scatter(산점도), hist(히스토그램), box(박스플롯), kde(밀도그래프)는 자주 활용
'기술이야기 (Technomian) > 데이터 분석 (Data Analysis)' 카테고리의 다른 글
| [데이터 분석] 텍스트 마이닝, 자연어로 구성된 글 속에서 가치 있는 정보를 추출하는 분석 방법 (0) | 2022.04.01 |
|---|---|
| [데이터 전처리] Preprocessing. 아웃라이어(outlier) 처리하기 (0) | 2021.10.24 |
| [데이터 전처리] Preprocessing. 결측치 (missing value) 처리하기 (0) | 2021.10.23 |